经典的编译链接模型
经典的编译模型,有以下的几个特点:
每一个源码文件通过汇编器(cc1)生成一个object文件
所有的object文件经过linker生成binary
这个模型有两个比较明显的缺点:
主要的优化都在生成objects这个阶段完成,无法进行全局的优化
在处理大规模的编译时,linker这一步耗时较长
LTO是什么 通常来说,优化时掌握的信息越多,最终的效果就越好。由小及大,编译的优化思路大致可以分为语句级优化,函数级优化,程序级优化等等。
在上面讨论经典的编译链接模型时,object内部的优化只需要修改汇编器(cc1)的实现即可。比较有难度的是进行objects之间的优化,比如去inline一个在其他源码文件中定义的全局函数。
在computer programming中讨论这种跨越objects的优化时,常用的概念叫Interprocedural optimization(IPO)。
与IPO相接近的一个概念,叫Whole Program Optimization(WPO)。
从上面的经典模型可以知道,有能力看到全部objects信息的,是linker。因此,具体到GCC的实现时,这种优化思路最主要的体现就是Link Time Optimization(LTO)。
LTO的发展历史 以下对LTO的发展历史整理,所用的资料都来自Honza Hubička的个人博客(见参考3)。
open64(2002)和LLVM(2003) 在2003年的GCC Summit上,Chris Lattner提出希望用LLVM取代当时正在开发中的Tree SSA,作为GCC的新middle-end,从而使GCC能够支持LTO。
鲜为人知的一个事情,2002年的时候,open64已经开源,并且作为一个能够支持全部LTO机制的GCC可选后端。
GCC3.4 引入–combine参数(2004) 2004年的时候,GCC3.4发布了。该版本开始,GCC通过实现LTO,开始支持了inter-module optimization(IMP)。
一般来说,LTO的实现通过把中间语言(intermediate language, IL)加入了objects文件中实现(本质是集中相关的程序逻辑后一起处理)。
当时的自由基金会担心这种IL的加入会让在不违反GPL2协议的情况下实现hook GCC成为可能。
Apple的工程师Geoff Keating是最早在GCC中引入IMP的人,这种机制允许GCC的front-end同时处理多个源码文件,并将处理好的多个源码文件作为一个整体传递给back-end。这种机制算是早期的WPO实现。
GCC4.0 接受了新的IL - Tree SSA(2005) LTO在GCC中的早期实现(2005) 2005年的时候,来自Google、IBM和Codesoucery的工程师们在GCC的email list中发布了一个正式的proposal - “Link-Time Optimization in GCC: Requirements and High-Level design “。这份文件列出了如果要支持LTO实现,现有的GCC需要做的一系列改变。
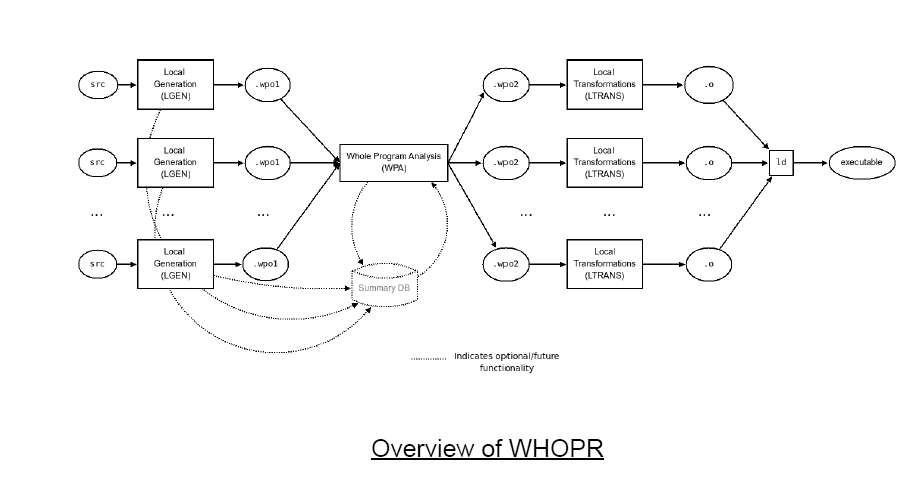
WHOPR: Whole program optization(2007) 由于LTO的实现需要庞大的工作量,在此期间,Google的工程师考虑一个另外的问题 - 如何使LTO支持大规模程序的编译。于是,一个新的proposal被提出 - “WHOPR - Fast and Scalable Whole Program Optimizations in GCC “
按照proposal中的提议,加入WHOPR之后,程序的编译链接模型变成了如下的形式:
整个优化过程主要分为三个步骤:
Local generation(LGEN)
Whole program analysis(WPA)
Local transformations(LTRANS)
LIPO(Profile Feedback Based Lightweight IPO) 相比于编译时做优化的思路,LIPO利用运行时的结果去指导优化策略的选择。
GCC4.5正式发布了LTO机制(2010) 在GCC4.5支持LTO之后,GCC4.6加入了对WHOPR的支持,同时移除了-fwhopr选项。该选项将作为-flto的默认子选项,用户仍让可以通过设置-flto-partition=none来关闭fwhopr选项。
GCC4.7+的版本开始支持kernel使用LTO机制(2012) GCC4.9(2014) GCC4.9对LTO机制做出了一系列的改进,用户感知最明显的是,LTO开启后,默认产生的是slim LTO文件,而不是fat LTO文件。所谓的fat LTO文件,是指同时产生原有的object源码以及LTO需要的IL文件。fat LTO文件的优点在于兼容性,对于那些不支持LTO的工具,依然可以继续按照object文件的原有流程去处理。缺点就是,fat LTO文件会带来双倍的编译耗时。随着工具链的发展完善,这种兼容性的设计就可以移除掉了。
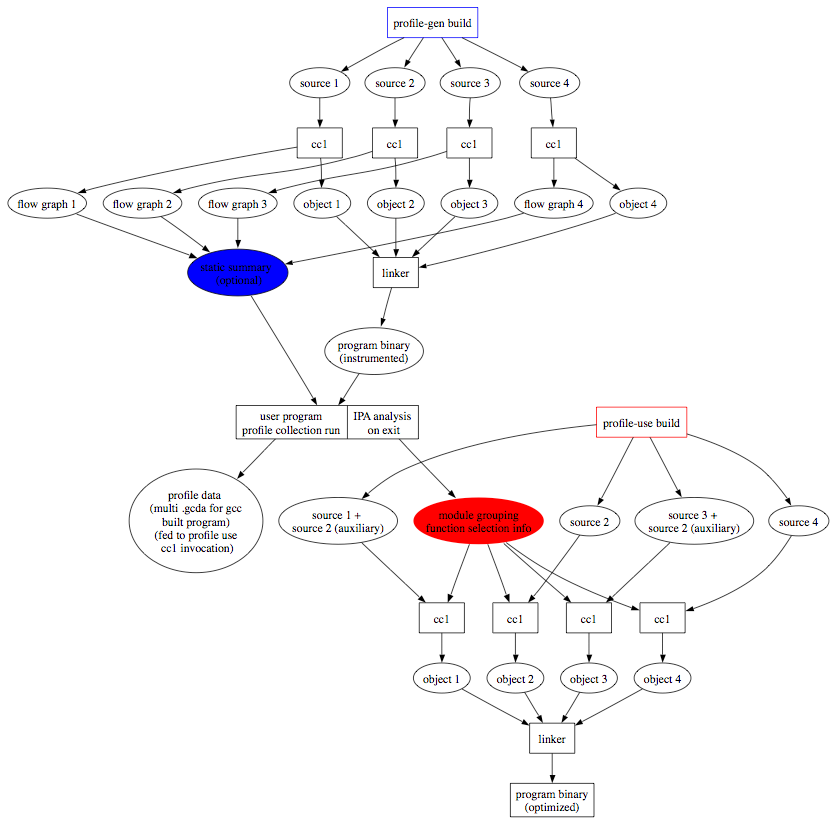
GCC5(2015) GCC5.0支持了Feedback Directed optimization(FDO)
按照GCC wiki 的说法,GCC的实现叫做LIPO,LIPO综合了IPO和FDO的优点,换句话说,利用FDO来改进IPO导致的编译时间长和耗费磁盘空间的问题。通过FDO,必要的优化分析可以从link time转移到run time进行。
完整的过程描述如图所示:
图片里的例子,build由4个source组成,经过run time的build analysis,source1需要cross module inline source2里的某些函数,source1在profile-use build时会把source2作为auxiliary一起编译。
从GCC8.1开始,linux发行版开始在构建中开启LTO机制。
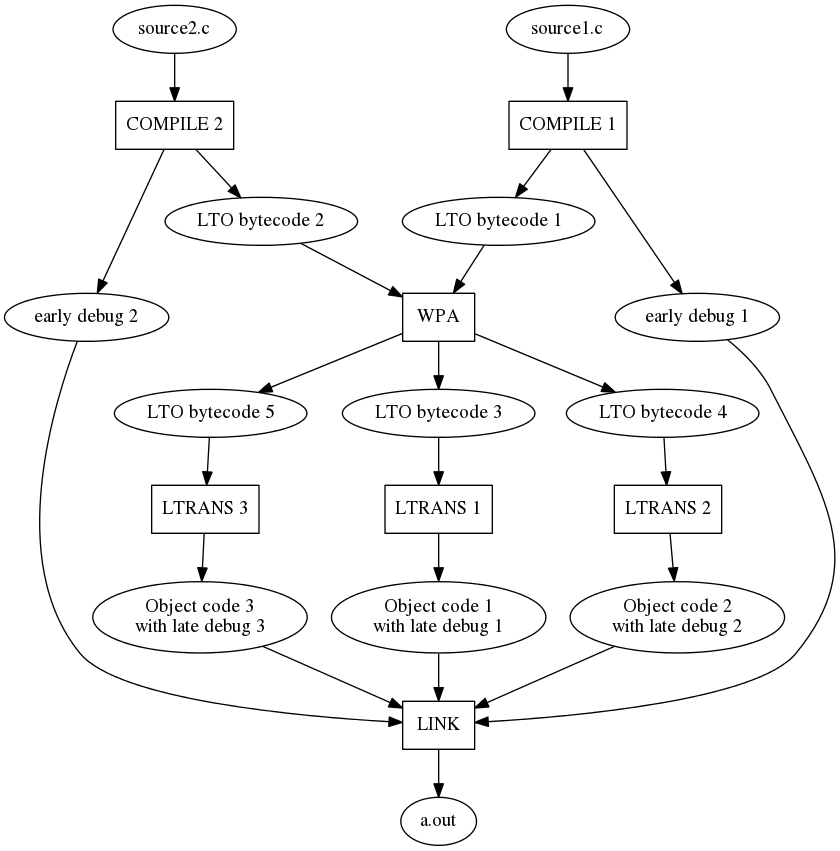
LTO机制长期存在的一个问题,就是编译输出和debug信息(主要是dwarf info)无法准确对应上。这一问题最终通过专门的项目early-debug 解决。
完整的过程如图所示:
在Link阶段,会对early debug阶段产生的debug信息进行选择,只选择必要的部分。
使用GCC9之后,针对测试使用的发行版版本,安装包的总量大小减少了5%,debug包减少了17%。
GCC9支持设置LTO使用时的并行度(flto=n),这个并行度会影响WPA阶段之后,划分成的子objects的数量。
可以认为,从GCC9开始,LTO机制逐渐稳定。
LTO相关的参数及编译产生的sections(GCC12) LTO编译相关的参数
开启LTO编译 - -flto
设置partion agrithom - -flto-partition=alg
开启LTO的增量编译 (supported from GCC 15)
-flto-incremental=path
-flto-incremental-cache-size=n
LTO objects生成时的压缩参数 - -flto-compression-level=n
控制是否产生fat objects - -ffat-lto-objects
所谓的fat object,是指产生的object中既包含了正常object code,还有LTO所需的IR。fat object的优点主要是兼容性,对于不支持LTO的工具链依然可以使用,在link阶段依然可以进行normal链接。缺点是编译耗时严重,产生的object过大。
LTO发展早期,GCC使能LTO机制之后,默认产生的为fat object。后期随着GNU工作链发展成熟,默认产生的object为slim object,即object只包含LTO需要的IR。
LTO的编译模式
LTO mode
WHOPR/partition mode (-flto=jobserver)
lto1的参数
-fwpa
-fltrans
-fltrans-output-list=file
-fresolution=file
dwarf相关的 - -fdump-earlydebug
.gnu.lto_.opts(Command line options)
.gnu.lto_.symtab(Symbol table)
.gnu.lto_.decls(Global declarations and types)
.gnu.lto_.cgraph(The callgraph)
.gnu.lto_.refs(IPA references)
.gnu.lto_.function_body.(Function bodies)
.gnu.lto_.vars(Static variable initializers)
.gnu.lto_.<jmpfuncs/pureconst/reference>(Summaries and optimization summaries used by IPA passes)
LTO开启后的编译过程 在不开启的LTO的情况下,C语言编译涉及到的组件有cc1,collect2,其中cc1生成objects文件,再通过collect2的调用,生成最终的binary。
在加入LTO之后,C语言编译的组件有cc1,collect2,lto1和lto-wrapper,其中lto1和lto-wrapper是针对LTO机制所增加的组件,以编译器插件的形式引入。
以redis 源码为例,开启LTO后,通过execsnoop观察进程的执行过程,可以得到以下的进程树(有省略):
可以看到,在原有的linker基础上,通过插件的方式引入lto-wrapper,对应上面的讨论,lto-wrapper分为两个过程:
WPA阶段:这阶段会读取全部的object信息,并且按照LTO的partion设置,重新划分成一定数量 的新object
ltrans阶段:将划分后的新object以一定的并发设置 重新进行编译
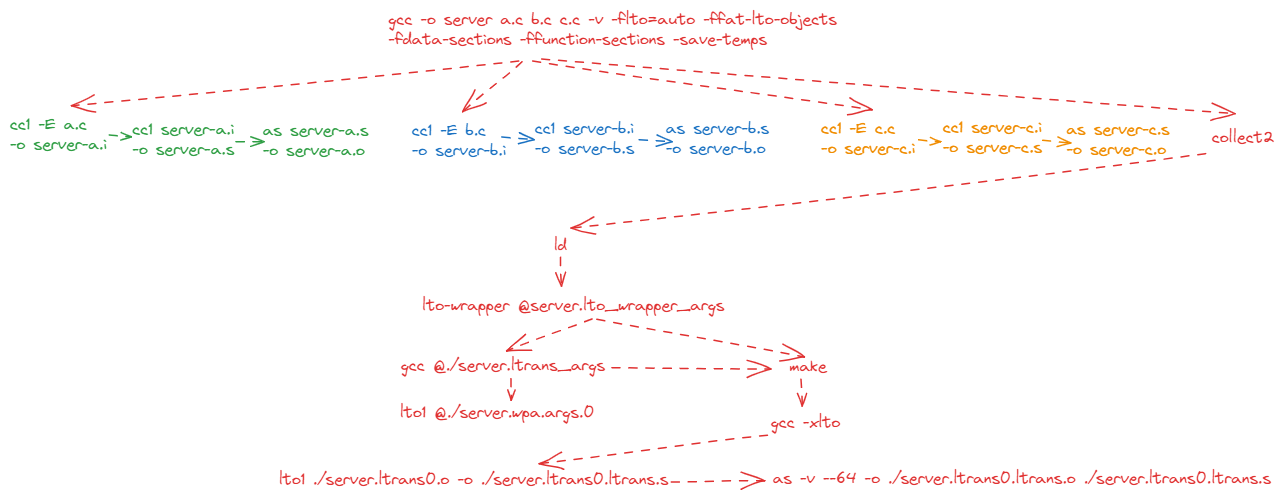
下面,我们以simple-ftp 的源码为例,来具体分析LTO的编译过程,以及中间文件的生成情况。
通过以下命令,编译server二进制:
1 gcc -v --save-temps -g -flto -ffat-lto-objects -fdata-sections -ffunction-sections -fdump-earlydebug server.c service.c siftp.c -o server
观察日志输出,可以得到以下编译输出(截取链接相关的部分):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 /usr/libexec/gcc/x86_64-redhat-linux/15/collect2 -plugin /usr/libexec/gcc/x86_64-redhat-linux/15/liblto_plugin.so -plugin-opt=/usr/libexec/gcc/x86_64-redhat-linux/15/lto-wrapper -plugin-opt=-fresolution=server.res -plugin-opt=-pass-through=-lgcc -plugin-opt=-pass-through=-lgcc_s -plugin-opt=-pass-through=-lc -plugin-opt=-pass-through=-lgcc -plugin-opt=-pass-through=-lgcc_s -flto --build-id --no-add-needed --eh-frame-hdr --hash-style=gnu -m elf_x86_64 -dynamic-linker /lib64/ld-linux-x86-64.so.2 -o server /usr/lib/gcc/x86_64-redhat-linux/15/../../../../lib64/crt1.o /usr/lib/gcc/x86_64-redhat-linux/15/../../../../lib64/crti.o /usr/lib/gcc/x86_64-redhat-linux/15/crtbegin.o -L/usr/lib/gcc/x86_64-redhat-linux/15 -L/usr/lib/gcc/x86_64-redhat-linux/15/../../../../lib64 -L/lib/../lib64 -L/usr/lib/../lib64 -L/usr/lib/gcc/x86_64-redhat-linux/15/../../.. -L/lib -L/usr/lib server-server.o server-service.o server-siftp.o -lgcc --push-state --as-needed -lgcc_s --pop-state -lc -lgcc --push-state --as-needed -lgcc_s --pop-state /usr/lib/gcc/x86_64-redhat-linux/15/crtend.o /usr/lib/gcc/x86_64-redhat-linux/15/../../../../lib64/crtn.o /usr/libexec/gcc/x86_64-redhat-linux/15/lto-wrapper -fresolution=server.res -flinker-output=exec server-server.o server-service.o server-siftp.o /usr/libexec/gcc/x86_64-redhat-linux/15/lto-wrapper -fresolution=server.res -flinker-output=exec server-server.o server-service.o server-siftp.o gcc @./server.ltrans_args Using built-in specs. COLLECT_GCC=gcc OFFLOAD_TARGET_NAMES=nvptx-none:amdgcn-amdhsa OFFLOAD_TARGET_DEFAULT=1 Target: x86_64-redhat-linux Configured with: ../configure --enable-bootstrap --enable-languages=c,c++,fortran,objc,obj-c++,ada,go,d,m2,cobol,lto --prefix=/usr --mandir=/usr/share/man --infodir=/usr/share/info --with-bugurl=http://bugzilla.redhat.com/bugzilla --enable-shared --enable-threads=posix --enable-checking=release --enable-multilib --with-system-zlib --enable-__cxa_atexit --disable-libunwind-exceptions --enable-gnu-unique-object --enable-linker-build-id --with-gcc-major-version-only --enable-libstdcxx-backtrace --with-libstdcxx-zoneinfo=/usr/share/zoneinfo --with-linker-hash-style=gnu --enable-plugin --enable-initfini-array --with-isl=/builddir/build/BUILD/gcc-15.0.1-build/gcc-15.0.1-20250329/obj-x86_64-redhat-linux/isl-install --enable-offload-targets=nvptx-none,amdgcn-amdhsa --enable-offload-defaulted --without-cuda-driver --enable-gnu-indirect-function --enable-cet --with-tune=generic --with-arch_32=i686 --build=x86_64-redhat-linux --with-build-config=bootstrap-lto --enable-link-serialization=1 Thread model: posix Supported LTO compression algorithms: zlib zstd gcc version 15.0.1 20250329 (Red Hat 15.0.1-0) (GCC) COLLECT_GCC_OPTIONS='-c' '-fno-openmp' '-fno-openacc' '-fno-pie' '-fcf-protection=none' '-g' '-v' '-save-temps' '-g' '-ffat-lto-objects' '-fdata-sections' '-ffunction-sections' '-fdump-earlydebug' '-mtune=generic' '-march=x86-64' '-fltrans-output-list=./server.ltrans.out' '-fwpa' '-fresolution=server.res' '-flinker-output=exec' /usr/libexec/gcc/x86_64-redhat-linux/15/lto1 -quiet -dumpbase ./server.wpa -mtune=generic -march=x86-64 -g -g -version -fno-openmp -fno-openacc -fno-pie -fcf-protection=none -ffat-lto-objects -fdata-sections -ffunction-sections -fdump-earlydebug -fltrans-output-list=./server.ltrans.out -fwpa -fresolution=server.res -flinker-output=exec @./server.wpa.args.0 GNU GIMPLE (GCC) version 15.0.1 20250329 (Red Hat 15.0.1-0) (x86_64-redhat-linux) compiled by GNU C version 15.0.1 20250329 (Red Hat 15.0.1-0), GMP version 6.3.0, MPFR version 4.2.2, MPC version 1.3.1, isl version isl-0.24-GMP GGC heuristics: --param ggc-min-expand=100 --param ggc-min-heapsize=131072 COMPILER_PATH=/usr/libexec/gcc/x86_64-redhat-linux/15/:/usr/libexec/gcc/x86_64-redhat-linux/15/:/usr/libexec/gcc/x86_64-redhat-linux/:/usr/lib/gcc/x86_64-redhat-linux/15/:/usr/lib/gcc/x86_64-redhat-linux/:/usr/libexec/gcc/x86_64-redhat-linux/15/:/usr/libexec/gcc/x86_64-redhat-linux/15/:/usr/libexec/gcc/x86_64-redhat-linux/:/usr/lib/gcc/x86_64-redhat-linux/15/:/usr/lib/gcc/x86_64-redhat-linux/ LIBRARY_PATH=/usr/lib/gcc/x86_64-redhat-linux/15/../../../../lib64/../lib64/:/lib/../lib64/../lib64/:/usr/lib/../lib64/../lib64/:/usr/lib/gcc/x86_64-redhat-linux/15/../../../../lib64/:/lib/../lib64/:/usr/lib/../lib64/:/usr/lib/gcc/x86_64-redhat-linux/15/:/usr/lib/gcc/x86_64-redhat-linux/15/../../../../lib64/:/lib/../lib64/:/usr/lib/../lib64/:/usr/lib/gcc/x86_64-redhat-linux/15/:/usr/lib/gcc/x86_64-redhat-linux/15/../../../../lib64/:/lib/../lib64/:/usr/lib/../lib64/:/usr/lib/gcc/x86_64-redhat-linux/15/../../../:/lib/:/usr/lib/:/usr/lib/gcc/x86_64-redhat-linux/15/../../../:/lib/:/usr/lib/ COLLECT_GCC_OPTIONS='-c' '-fno-openmp' '-fno-openacc' '-fno-pie' '-fcf-protection=none' '-g' '-v' '-save-temps' '-g' '-ffat-lto-objects' '-fdata-sections' '-ffunction-sections' '-fdump-earlydebug' '-mtune=generic' '-march=x86-64' '-fltrans-output-list=./server.ltrans.out' '-fwpa' '-fresolution=server.res' '-flinker-output=exec' '-dumpdir' './server.wpa.' [Leaving LTRANS ./server.ltrans.out] gcc @./server.ltrans0.ltrans_args Using built-in specs. COLLECT_GCC=gcc OFFLOAD_TARGET_NAMES=nvptx-none:amdgcn-amdhsa OFFLOAD_TARGET_DEFAULT=1 Target: x86_64-redhat-linux Configured with: ../configure --enable-bootstrap --enable-languages=c,c++,fortran,objc,obj-c++,ada,go,d,m2,cobol,lto --prefix=/usr --mandir=/usr/share/man --infodir=/usr/share/info --with-bugurl=http://bugzilla.redhat.com/bugzilla --enable-shared --enable-threads=posix --enable-checking=release --enable-multilib --with-system-zlib --enable-__cxa_atexit --disable-libunwind-exceptions --enable-gnu-unique-object --enable-linker-build-id --with-gcc-major-version-only --enable-libstdcxx-backtrace --with-libstdcxx-zoneinfo=/usr/share/zoneinfo --with-linker-hash-style=gnu --enable-plugin --enable-initfini-array --with-isl=/builddir/build/BUILD/gcc-15.0.1-build/gcc-15.0.1-20250329/obj-x86_64-redhat-linux/isl-install --enable-offload-targets=nvptx-none,amdgcn-amdhsa --enable-offload-defaulted --without-cuda-driver --enable-gnu-indirect-function --enable-cet --with-tune=generic --with-arch_32=i686 --build=x86_64-redhat-linux --with-build-config=bootstrap-lto --enable-link-serialization=1 Thread model: posix Supported LTO compression algorithms: zlib zstd gcc version 15.0.1 20250329 (Red Hat 15.0.1-0) (GCC) COLLECT_GCC_OPTIONS='-c' '-fno-openmp' '-fno-openacc' '-fno-pie' '-fcf-protection=none' '-g' '-v' '-save-temps' '-g' '-ffat-lto-objects' '-fdata-sections' '-ffunction-sections' '-fdump-earlydebug' '-mtune=generic' '-march=x86-64' '-fltrans' '-o' './server.ltrans0.ltrans.o' /usr/libexec/gcc/x86_64-redhat-linux/15/lto1 -quiet -dumpbase ./server.ltrans0.ltrans -mtune=generic -march=x86-64 -g -g -version -fno-openmp -fno-openacc -fno-pie -fcf-protection=none -ffat-lto-objects -fdata-sections -ffunction-sections -fdump-earlydebug -fltrans @./server.ltrans0.ltrans.args.0 -o ./server.ltrans0.ltrans.s GNU GIMPLE (GCC) version 15.0.1 20250329 (Red Hat 15.0.1-0) (x86_64-redhat-linux) compiled by GNU C version 15.0.1 20250329 (Red Hat 15.0.1-0), GMP version 6.3.0, MPFR version 4.2.2, MPC version 1.3.1, isl version isl-0.24-GMP GGC heuristics: --param ggc-min-expand=100 --param ggc-min-heapsize=131072 COLLECT_GCC_OPTIONS='-c' '-fno-openmp' '-fno-openacc' '-fno-pie' '-fcf-protection=none' '-g' '-v' '-save-temps' '-g' '-ffat-lto-objects' '-fdata-sections' '-ffunction-sections' '-fdump-earlydebug' '-mtune=generic' '-march=x86-64' '-fltrans' '-o' './server.ltrans0.ltrans.o' as -v --gdwarf-5 --64 -o ./server.ltrans0.ltrans.o ./server.ltrans0.ltrans.s GNU assembler version 2.44 (x86_64-redhat-linux) using BFD version version 2.44-3.fc42 COMPILER_PATH=/usr/libexec/gcc/x86_64-redhat-linux/15/:/usr/libexec/gcc/x86_64-redhat-linux/15/:/usr/libexec/gcc/x86_64-redhat-linux/:/usr/lib/gcc/x86_64-redhat-linux/15/:/usr/lib/gcc/x86_64-redhat-linux/:/usr/libexec/gcc/x86_64-redhat-linux/15/:/usr/libexec/gcc/x86_64-redhat-linux/15/:/usr/libexec/gcc/x86_64-redhat-linux/:/usr/lib/gcc/x86_64-redhat-linux/15/:/usr/lib/gcc/x86_64-redhat-linux/ LIBRARY_PATH=/usr/lib/gcc/x86_64-redhat-linux/15/../../../../lib64/../lib64/:/lib/../lib64/../lib64/:/usr/lib/../lib64/../lib64/:/usr/lib/gcc/x86_64-redhat-linux/15/../../../../lib64/:/lib/../lib64/:/usr/lib/../lib64/:/usr/lib/gcc/x86_64-redhat-linux/15/:/usr/lib/gcc/x86_64-redhat-linux/15/../../../../lib64/:/lib/../lib64/:/usr/lib/../lib64/:/usr/lib/gcc/x86_64-redhat-linux/15/:/usr/lib/gcc/x86_64-redhat-linux/15/../../../../lib64/:/lib/../lib64/:/usr/lib/../lib64/:/usr/lib/gcc/x86_64-redhat-linux/15/../../../:/lib/:/usr/lib/:/usr/lib/gcc/x86_64-redhat-linux/15/../../../:/lib/:/usr/lib/ COLLECT_GCC_OPTIONS='-c' '-fno-openmp' '-fno-openacc' '-fno-pie' '-fcf-protection=none' '-g' '-v' '-save-temps' '-g' '-ffat-lto-objects' '-fdata-sections' '-ffunction-sections' '-fdump-earlydebug' '-mtune=generic' '-march=x86-64' '-fltrans' '-o' './server.ltrans0.ltrans.o' '-dumpdir' './server.ltrans0.ltrans.' [Leaving LTRANS ./server.ltrans0.o] [Leaving server.lto_wrapper_args] [Leaving ./server.ltrans0.ltrans.o] [Leaving server-server.o.debug.temp.o] [Leaving server-service.o.debug.temp.o] [Leaving server-siftp.o.debug.temp.o] COLLECT_GCC_OPTIONS='-v' '-save-temps' '-g' '-flto' '-ffat-lto-objects' '-fdata-sections' '-ffunction-sections' '-fdump-earlydebug' '-o' 'server' '-mtune=generic' '-march=x86-64' '-dumpdir' 'server.'
接下来,按照执行的先后顺序,分为三个阶段,讨论上面的日志。
lto-wrapper的执行命令,以及生成的中间文件 详细的命令可以在上面的日志内查看,当前目录下会生成一个server.lto_wrapper_args,其中的内容为:
1 2 3 4 5 -fresolution=server.res -flinker-output=exec server-server.o server-service.o server-siftp.o
server.res 按照文档的说法,叫linker resolution file,包含的内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 3 server-server.o 40 195 95b25203115d8f9a PREVAILING_DEF_IRONLY sigchld_handler 206 95b25203115d8f9a PREVAILING_DEF_IRONLY service_create 210 95b25203115d8f9a PREVAILING_DEF_IRONLY session_create 348 95b25203115d8f9a PREVAILING_DEF_IRONLY service_handleCmd 355 95b25203115d8f9a PREVAILING_DEF_IRONLY g_pwd 359 95b25203115d8f9a PREVAILING_DEF_IRONLY service_loop 365 95b25203115d8f9a PREVAILING_DEF main 339 95b25203115d8f9a RESOLVED_DYN stderr 373 95b25203115d8f9a RESOLVED_DYN wait 377 95b25203115d8f9a RESOLVED_DYN close 385 95b25203115d8f9a RESOLVED_DYN perror 394 95b25203115d8f9a RESOLVED_DYN listen 412 95b25203115d8f9a RESOLVED_DYN bind 422 95b25203115d8f9a RESOLVED_DYN setsockopt 430 95b25203115d8f9a RESOLVED_DYN socket 442 95b25203115d8f9a RESOLVED_DYN htons 451 95b25203115d8f9a RESOLVED_DYN htonl 493 95b25203115d8f9a RESOLVED_IR siftp_send 515 95b25203115d8f9a RESOLVED_IR service_query 520 95b25203115d8f9a RESOLVED_IR siftp_recv 526 95b25203115d8f9a RESOLVED_IR service_sendStatus 551 95b25203115d8f9a RESOLVED_IR service_writeFile 556 95b25203115d8f9a RESOLVED_IR siftp_recvData 562 95b25203115d8f9a RESOLVED_IR service_statTest 567 95b25203115d8f9a RESOLVED_IR service_permTest 573 95b25203115d8f9a RESOLVED_IR service_getAbsolutePath 579 95b25203115d8f9a RESOLVED_IR siftp_sendData 584 95b25203115d8f9a RESOLVED_IR service_readFile 589 95b25203115d8f9a RESOLVED_IR service_handleCmd_chdir 605 95b25203115d8f9a RESOLVED_IR service_readDir 611 95b25203115d8f9a RESOLVED_IR service_freeArgs 616 95b25203115d8f9a RESOLVED_IR service_parseArgs 618 95b25203115d8f9a RESOLVED_IR session_destroy 634 95b25203115d8f9a RESOLVED_DYN inet_ntoa 639 95b25203115d8f9a RESOLVED_DYN ntohs 649 95b25203115d8f9a RESOLVED_DYN accept 663 95b25203115d8f9a RESOLVED_DYN sigaction 675 95b25203115d8f9a RESOLVED_DYN sigemptyset 701 95b25203115d8f9a RESOLVED_DYN __isoc23_strtol 709 95b25203115d8f9a RESOLVED_DYN realpath server-service.o 30 201 bea4b8cdcb05e1ce PREVAILING_DEF_IRONLY session_destroy 216 bea4b8cdcb05e1ce PREVAILING_DEF_IRONLY service_query 230 bea4b8cdcb05e1ce PREVAILING_DEF_IRONLY service_getAbsolutePath 236 bea4b8cdcb05e1ce PREVAILING_DEF_IRONLY service_sendStatus 242 bea4b8cdcb05e1ce PREVAILING_DEF_IRONLY service_freeArgs 247 bea4b8cdcb05e1ce PREVAILING_DEF_IRONLY service_parseArgs 249 bea4b8cdcb05e1ce PREVAILING_DEF_IRONLY service_recvStatus 254 bea4b8cdcb05e1ce PREVAILING_DEF_IRONLY remote_exec 259 bea4b8cdcb05e1ce PREVAILING_DEF_IRONLY service_readDir 387 bea4b8cdcb05e1ce PREVAILING_DEF_IRONLY service_writeFile 392 bea4b8cdcb05e1ce PREVAILING_DEF_IRONLY service_permTest 398 bea4b8cdcb05e1ce PREVAILING_DEF_IRONLY service_statTest 403 bea4b8cdcb05e1ce PREVAILING_DEF_IRONLY service_handleCmd_chdir 405 bea4b8cdcb05e1ce PREVAILING_DEF_IRONLY service_readFile 381 bea4b8cdcb05e1ce RESOLVED_DYN stderr 410 bea4b8cdcb05e1ce RESOLVED_IR siftp_send 445 bea4b8cdcb05e1ce RESOLVED_IR siftp_recv 454 bea4b8cdcb05e1ce RESOLVED_DYN realpath 495 bea4b8cdcb05e1ce RESOLVED_DYN strtok 552 bea4b8cdcb05e1ce RESOLVED_DYN closedir 561 bea4b8cdcb05e1ce RESOLVED_DYN readdir 577 bea4b8cdcb05e1ce RESOLVED_DYN perror 587 bea4b8cdcb05e1ce RESOLVED_DYN opendir 620 bea4b8cdcb05e1ce RESOLVED_DYN fclose 639 bea4b8cdcb05e1ce RESOLVED_DYN fopen 652 bea4b8cdcb05e1ce RESOLVED_DYN stat 663 bea4b8cdcb05e1ce RESOLVED_DYN fread 669 bea4b8cdcb05e1ce RESOLVED_DYN rewind 675 bea4b8cdcb05e1ce RESOLVED_DYN ftell 683 bea4b8cdcb05e1ce RESOLVED_DYN fseek server-siftp.o 14 210 a37c7c5be2356b4 PREVAILING_DEF_IRONLY Message_create 214 a37c7c5be2356b4 PREVAILING_DEF_IRONLY Message_destroy 219 a37c7c5be2356b4 PREVAILING_DEF_IRONLY siftp_escape 343 a37c7c5be2356b4 PREVAILING_DEF_IRONLY siftp_unescape 356 a37c7c5be2356b4 PREVAILING_DEF_IRONLY siftp_serialize 361 a37c7c5be2356b4 PREVAILING_DEF_IRONLY siftp_deserialize 366 a37c7c5be2356b4 PREVAILING_DEF_IRONLY siftp_send 371 a37c7c5be2356b4 PREVAILING_DEF_IRONLY siftp_recv 377 a37c7c5be2356b4 PREVAILING_DEF_IRONLY siftp_sendData 382 a37c7c5be2356b4 PREVAILING_DEF_IRONLY siftp_recvData 341 a37c7c5be2356b4 RESOLVED_DYN stderr 477 a37c7c5be2356b4 RESOLVED_DYN perror 486 a37c7c5be2356b4 RESOLVED_DYN send 493 a37c7c5be2356b4 RESOLVED_DYN recv
WPA的执行过程,以及生成的中间文件 通过lto-wrapper,通过以下gcc命令发起WPA分析:
1 /usr/bin/gcc @./server.ltrans_args
server.ltrans_args对应的内容为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 -xlto -c -fno-openmp -fno-openacc -fno-pie -fcf-protection=none -g -mtune=generic -march=x86-64 -v -save-temps -g -ffat-lto-objects -fdata-sections -ffunction-sections -fdump-earlydebug -mtune=generic -march=x86-64 -dumpdir server. -dumpbase ./server.wpa -fltrans-output-list=./server.ltrans.out -fwpa -fresolution=server.res -flinker-output=exec server-server.o server-service.o server-siftp.o
接下来,gcc会调用lto1,命令为:
1 /usr/libexec/gcc/x86_64-redhat-linux/15/lto1 -quiet -dumpbase ./server.wpa -mtune=generic -march=x86-64 -g -g -version -fno-openmp -fno-openacc -fno-pie -fcf-protection=none -ffat-lto-objects -fdata-sections -ffunction-sections -fdump-earlydebug -fltrans-output-list=./server.ltrans.out -fwpa -fresolution=server.res -flinker-output=exec @./server.wpa.args.0
server.wpa.args.0对应的内容为:
1 2 3 server-server.o server-service.o server-siftp.o
server.wpa.args.0包含的内容对应了input objects,即原始的object文件列表。
此处的server.ltrans0.o是wpa阶段的输入,作为ltrans的输入,进入下一阶段的处理。
ltrans的执行过程,以及生成的中间文件 根据WPA阶段的划分结果,会生成一个make文件,make文件里生成了每个ltrans文件的编译命令,按照并行度设置,这里每个ltrans文件的编译是单独运行的。本文的例子里,只生成了一个ltrans文件,直接运行的gcc命令。
对应的gcc命令为:
1 /usr/bin/gcc @./server.ltrans0.ltrans_args
server.ltrans0.ltrans_args对应的内容为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 -xlto -c -fno-openmp -fno-openacc -fno-pie -fcf-protection=none -g -mtune=generic -march=x86-64 -v -save-temps -g -ffat-lto-objects -fdata-sections -ffunction-sections -fdump-earlydebug -mtune=generic -march=x86-64 -dumpdir server. -dumpbase ./server.ltrans0.ltrans -fltrans -o ./server.ltrans0.ltrans.o ./server.ltrans0.o
gcc接下来会调用lto1,对应的命令为:
1 /usr/libexec/gcc/x86_64-redhat-linux/15/lto1 -quiet -dumpbase ./server.ltrans0.ltrans -mtune=generic -march=x86-64 -g -g -version -fno-openmp -fno-openacc -fno-pie -fcf-protection=none -ffat-lto-objects -fdata-sections -ffunction-sections -fdump-earlydebug -fltrans @./server.ltrans0.ltrans.args.0 -o ./server.ltrans0.ltrans.s
server.ltrans0.ltrans.args.0的内容为:
lto1结束后,gcc会调用as生成最终的object,对应的命令为:
1 as -v --gdwarf-5 --64 -o ./server.ltrans0.ltrans.o ./server.ltrans0.ltrans.s
以GCC15为例,分析LTO的源码实现
collect2如何调用lto-wrapper
lto-wrapper的源码由两部分组成,一部分以so的形式,在linker运行时,以插件的形式引入,另一部分则是编译成lto-wrapper可执行文件。gcc和lto-wrapper之间存在嵌套的调用关系,因此理解起来有点困难。个人理解,lto-wrapper的引入,在链接的时候需要进行再次编译,让编译和链接之间的关系变得界限没有那么清晰。
LTO的partion过程
partion的过程在WPA阶段完成,此处有两个参数需要区别,一个是最终划分的lto objects数量,另一个是在ltrans阶段编译时的并行度。这两者没有关联关系,后者主要有系统的核数决定,前者则是有一个默认值。一开始我把这两个参数搞混了,一直在纠结第一个参数跟核数相关的话,如何保证二进制的编译一致性。
lto1的实现入口为: gcc/lto/lto.cc
当前支持的partion algorithm如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 if (flag_ipa_reorder_for_locality) lto_locality_map (param_max_locality_partition_size); else if (flag_lto_partition == LTO_PARTITION_1TO1) lto_1_to_1_map (); else if (flag_lto_partition == LTO_PARTITION_MAX) lto_max_map (); else if (flag_lto_partition == LTO_PARTITION_ONE) lto_balanced_map (1, INT_MAX); else if (flag_lto_partition == LTO_PARTITION_BALANCED) lto_balanced_map (param_lto_partitions, param_max_partition_size); else if (flag_lto_partition == LTO_PARTITION_CACHE) lto_cache_map (param_lto_partitions, param_max_partition_size);
具体的划分过程就不在此处赘述了,直接看对应的函数即可。
经过ltrans生成的object如何对应dwarf信息 - early debug
实际使用的时候,发现最终生成的lto objects对应的dwarf信息缺失很多。经过对dwarf标准的阅读,发现这是LTO项目本身的问题。为了解决这一问题,LTO项目使用了earlydebug,通过参数-fdump-earlydebug,可以把每个lto object对应的earlydebug信息dump出来。当前没有发现工具可以把earlydebug信息和lto object merge到一起的工具,这部分内容还需要继续阅读dwarf标准和gcc的earlydebug实现来补充。
补充信息 - DWARF信息的组成以及占用的大小比例
Debug Information Entries - .debug_info (11%): This table contains the debug info for subprograms and variables defined in the program, and many of the trivial types used.
Type Units - .debug_types (12%): This table contains the debug info for most of the non-trivial types (e.g., structs and classes, enums, typedefs), keyed by a hashed type signature so that duplicate type definitions can be eliminated by the linker. During the link, about 85% of this data is discarded as duplicate. These sections have the same structure as the .debug_info sections.
Strings - .debug_str (25%): This table contains strings that are not placed inline in the .debug_info and .debug_types sections. The linker merges the string tables to eliminate duplicates, discarding about 93% of the data as duplicate.
Range tables - .debug_ranges (2%) and .debug_aranges (0.1%): These tables contain range lists to define what pieces of a program’s text belong to which subprograms and compilation units.
Location lists - .debug_loc (2%): These tables contain lists of expressions that describe to the debugger the location of a variable based on the PC value.
Line number tables - .debug_line (1%): These tables contain a description of the mapping from PC values to source locations.
Debug abbreviation codes - .debug_abbrev (<1%): These tables provide the definitions for abbreviation codes used in describing the debug info in the .debug_info and .debug_types sections.
Public names - .debug_pubnames (<1%): These tables provide a list of public names defined in the compilation unit, intended to allow the debugger to find the appropriate compilation units quickly for a given name. (In practice, these tables are unused by gdb.)
Relocations for debug information (46%): The relocations identify to the linker where all the relocatable references are in the debug information. Of the 46%, about 20 percentage points are for the .debug_info section and about 17 are for the .debug_types section. Nine of ten of these relocations are for references to the .debug_str section; the remaining tenth are mostly references to locations in the program. Another 9 percentage points are for the .debug_ranges and .debug_loc sections; these are entirely references to locations in the program. These relocations are used by the linker and are not copied to the output file.
发行版使用的LTO参数 fedora使用的编译参数通过rpm包redhat-rpm-config引入,解开这个包,可以发现以下LTO相关的编译参数:
1 2 3 %_gcc_lto_cflags -flto=auto -ffat-lto-objects %_clang_lto_cflags -flto=thin -ffat-lto-objects %_lto_cflags %{expand:%%{_%{toolchain}_lto_cflags}}
其他发行版的使用情况可以参考以下wiki:
参考链接
Interprocedural_optimization CS232 Honza Hubička’s Blog GCC-Wiki-DebugFission

")