
最近在编写一个借助Dwarf格式实现的调测工具,搜集材料时,发现互联网世界对Dwarf的讨论相当稀少。想要熟悉Dwarf,最可靠的材料除了晦涩复杂的标准文档,只能是已有的Dwarf解析工具,包括但不限于gdb、llvm-dwarfdump等等。在经历无数的踩坑之后,记录下这个过程中学习掌握到的Dwarf格式实现细节。
Dwarf是什么
Dwarf是当前最广泛使用的标准调测格式,其最初伴随ELF格式一起发布,当前已经独立于ELF发展,支持多种可执行文件格式。Dwarf最新的标准为Dwarf 5,实际使用中,广泛使用的版本包含Dwarf 4和Dwarf 5。本文讨论的实现细节仅限于Dwarf 4和Dwarf 5。
学习Dwarf标准需要具备的前置知识
LEB128编码
LEB128,全称是Little Endian Base 128,是一种支持将任意大的整数编码到变长字节流的可变长度编码。LEB128在Dwarf格式和WebAssembly中大量使用。LEB128可以分为Unsigned LEB128以及Signed LEB128。在解码开始前,必须先阅读标准确定对应的数是Unsigned或者Signed(即符号信息本身不会被编码到整数中)。
Unsigned LEB128的编码过程:
- 将该数用二进制表示
- 通过前置添0的方式将二进制位的长度填充为7的长度
- 将二进制数分成7位一组
- 除最高有效位外,其余组均在高1位上添加1
简单的说,Unsigned LEB128的每个byte的最高位通过置1来表示,是否还需要使用下一个Byte。
Signed LEB128的编码过程:以N(N%7 == 0)位二进制补码表示需要表示的数,然后按照Unsigned LEB128的方式编码。
Dwarf信息的格式和内容表示格式是分离的。
这句话听起来有点拗口,我将通过一个例子,来表示这句话的含义。
在Dwarf中,为了节约空间,将.debug_info中每个entry对应的格式信息都存储在.debug_abbrev中。这样在.debug_info中,只需要通过一个Abbrev Number,就可以快速知道某个Entry的格式。比如以下是从某个object文件的.debug_abbrev中读取的部分:
1 | [9] DW_TAG_variable DW_CHILDREN_no |
对应的.debug_info使用样例为:
1 | 0x000089c1: DW_TAG_variable [9] (0x00008281) |
这里包含了两种格式,一种是内容本身的组织格式,即表示的是一个variable,由一个DW_AT_abstract_origin(源码路径)和DW_AT_location组成(地址)。另一种是内容本身的表示格式,DW_AT_abstract_origin的格式是DW_FORM_ref_addr(符号引用地址),DW_AT_location的DW_FORM_exprloc(需要通过堆栈计算机推导产生的地址)。
object文件的Dwarf信息会存在大量的重定向条目,直接读取出来的信息是不准确的
以上文提到的例子为例,由于object文件还没有经过link阶段,dwarf信息中地址大多都是临时的,只看如下信息没法获得任何结论:
1 | 0x000089c1: DW_TAG_variable [9] (0x00008281) |
这时候,如果想要解析对应的信息,就要对照内存偏移和重定向条目来看,对应的重定向条目为:
1 | 00000000000089c2 000001890000000a R_X86_64_32 0000000000000000 rdb.c.0b078eae + 8471 |
这里就能看出,这个entry表示的信息为有一个变量.bss.info_updated_time.0,来自源码文件rdb.c.0b078eae,addend信息猜测是表示行列信息,由于实际实现中,没有使用,未做探究。
至于89c2和89c8的计算过程,则需要结合格式信息来做判断了。
通过有限状态机来表示信息
目前已知的,Dwarf格式中有两处通过有限状态自动机来表示信息:
- 上文提到的DW_FORM_exprloc,通过一个简单的堆栈计算机来推到内存地址
- .debug_line中通过有限状态计算机指令,来生成庞大的表格,来映射内存地址和源码位置,实际实现中,包含了一堆指令,某些指令用来指明某一行的结束。
这么做的好处是通过时间换空间,大量重复的信息可以被压缩。
Dwarf信息概览
dwarf涉及的section很多,最终都会呈现到.debug_info中。比如.debug_abbrev表示内容格式,常见的格式存储的内容如下:
.debug_abbrev, 存储.debug_info中使用的缩写信息;
.debug_arranges, 存储一个加速访问的查询表,通过内存地址查询对应编译单元信息;
.debug_frame, 存储调用栈帧信息;
.debug_info, 存储核心DWARF数据,包含了描述变量、代码等的DIEs;
.debug_line, 存储行号表程序 (程序指令由行号表状态机执行,执行后构建出完整的行号表)
.debug_loc, 存储location描述信息;
.debug_macinfo, 存储宏相关描述信息;
.debug_pubnames, 存储一个加速访问的查询表,通过名称查询全局对象和函数;
.debug_pubtypes, 存储一个加速访问的查询表,通过名称查询全局类型;
.debug_ranges, 存储DIEs中引用的address ranges;
.debug_str, 存储.debug_info中引用的字符串表,也是通过偏移量来引用;
.debug_types, 存储描述数据类型相关的DIEs;
dwarf info的组织形式是Unit-Entry-Attr的树形方式。
一个Unit表示一个编译单元,一个Entry表示Unit中的一个项,可以是subprogram、variable、parameter等等,Attr则是描述每个Entry的具体信息。
可以参考如下图来理解Dwarf Section之间的关联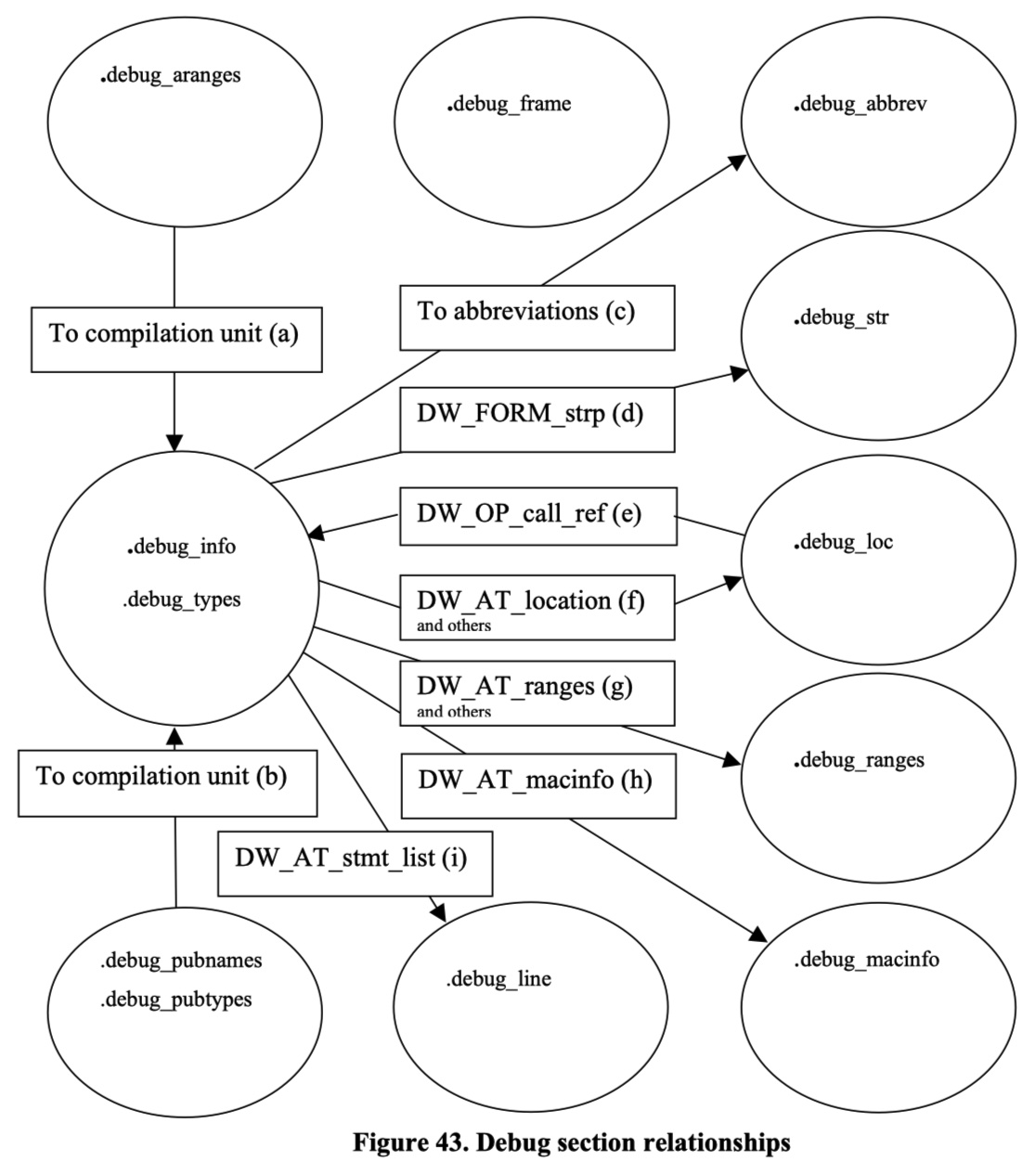
.debug_line信息的计算过程
如上文所述, .debug_line存储的是一个有限状态机的计算过程,最终生成的是一个line table,如下所示:
1 | Address Line Column File ISA Discriminator OpIndex Flags |
.debug_line的最开始一个heder,记录了当前line table的元信息,其中需要关注的是其中包含了一个directory table和file table。每个file table会关联一个directory table表项,从而形成一个完整的路径。此处有一个细节,如果最终的路径是一个相对路径,则需要以irectory table的第0项为base,形成一个绝对路径,Dwarf5标准对这一实现的说明如下:
1 | The first entry is the current directory of the compilation. Each additional |
接着header,则是一个针对以下状态机的转化指令数组。
1 | struct StateMachineRegisters { |
当前读到较为清晰的.debug_line实现是gdb中的实现,其中需要关注的细节是,view的变化表示换行。